目标检测
使用本地目标检测器实时检测动态目标
如:人、车、安全风险(刀枪、烟火、化学品泄露等)
内置多种检测器类型
cpu、edgetpu、onnx、openvino、rocm 和 tensorrt
高推理速度
Yolo-NAS-S | MobileDet
320 x 320
5 毫秒
广泛的硬件支持
Nvidia GPU/Jetson
Intel Arc GPU | AMD GPU
Google Coral EdgeTPU
自制数据集
从零开始训练
没有商业化限制
可生产型部署
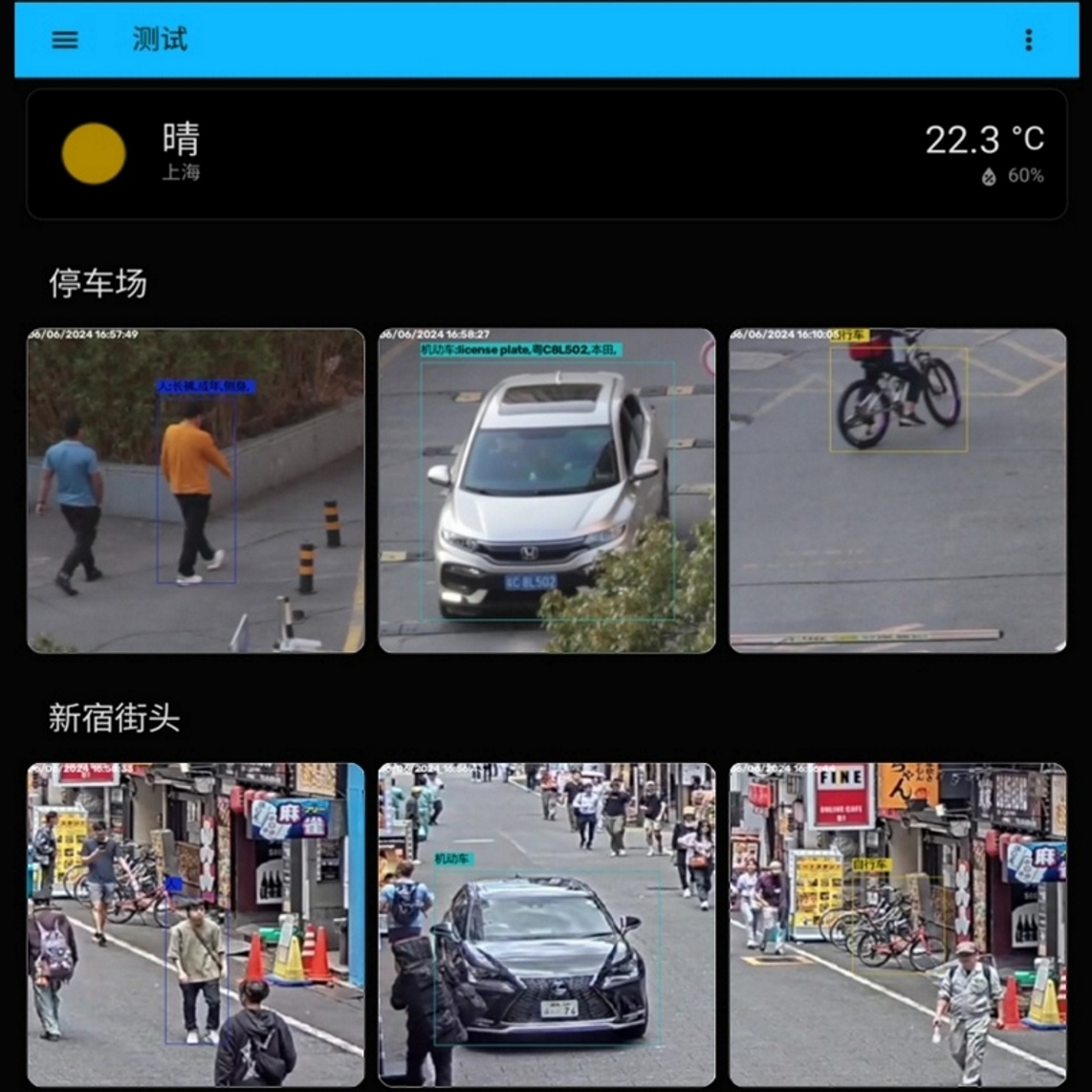
特征识别
在拍不到人脸和车牌的情况下
使用 ReID 识别人车外形特征
行人特征
头部
帽子、眼镜
服装颜色
白、黑、红、橙、黄、粉、深蓝、蓝、绿、灰、紫
上身
短袖、长袖、条纹、图案、撞色/多色、格子
下身
条纹、图案、长裤、短裤、裙子、靴子
携带
手提包、肩包、背包、手持物品
年龄
老年、成年、未成年
姿态
正身、侧身、背面
性别
男、女
车辆特征
类别
轿车、SUV、MPV、面包车、卡车、皮卡、巴士、超跑
颜色
金、棕、绿、黄、银、灰、浅蓝、黑、白、蓝、红、粉、橙、紫
品牌
比亚迪、蔚来、特斯拉、大众、本田、丰田、奥迪、日产、宝马、广汽、奔驰、长安、别克、吉利、领克、哈弗、福特、沃尔沃、奇瑞、五菱、标致、雪佛兰、马自达、保时捷、雷克萨斯、凯迪拉克、名爵、现代
车型
小米·su7、秦L、Model-3|Model-Y、帕萨特·2019-2021、问界M9、MEGA等约400多种车型
语义搜索
用被跟踪目标的图像和文本描述创建嵌入(数值向量表示)来实现。通过比较这些嵌入,评估它们的相似性,从而提供相关的搜索结果。
相似度搜索
使用Jina AI CLIP 模型能够将图像和文本嵌入到相同的向量空间中,从而实现"图像 -> 文本"和"文本 -> 图像"的相似度搜索。
生成式 AI
生成式 AI(通过 Ollama 自托管的大型语言模型、Google Gemini 和 OpenAI)根据目标的缩略图自动生成描述性文本。为被跟踪的目标提供更多上下文信息。不仅识别场景中的“什么”,还推断“为什么”他可能在那里或“接下来”他可能会做什么。
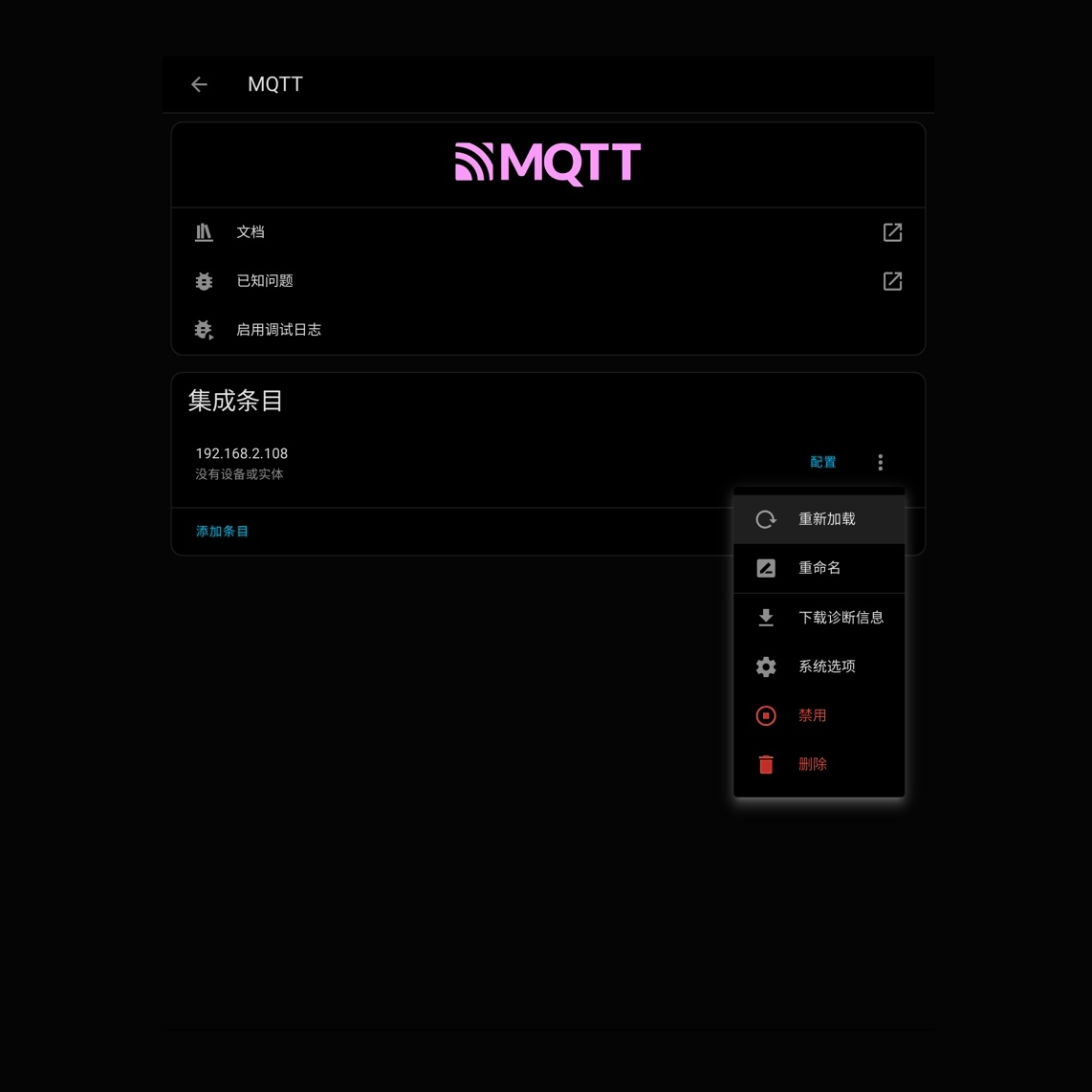
智能物联
支持通过 MQTT 协议接入物联网
通过插件与 Home Assistant 集成实现继电器、照明、电器、UPS 等的联动控制。
提供了一个 MQTT topic,当您的生成式 AI 返回跟踪目标的描述时,该 topic 会更新为包含 event_id 和 description 的 JSON 有效负载。此描述可以直接用于通知,例如发送警报到您的手机或进行音频公告。
 | 机器视觉解决方案
| 机器视觉解决方案
监测任意安全攸关场景